Google Street View offers panoramic views of more or less any city street in much of the developed world, as well as views along countless footpaths, inside shopping malls, and around museums and art galleries. It is an extraordinary feat of modern engineering that is changing the way we think about the world around us.
But while Street View can show us what distant places look like, it does not show what the process of traveling or exploring would be like. It’s easy to come up with a fix: simply play a sequence of Street View Images one after the other to create a movie.
But that doesn’t work as well as you might imagine. Running these images at 25 frames per second or thereabouts makes the scenery run ridiculously quickly. That may be acceptable when the scenery does not change, perhaps along freeways and motorways or through unchanging landscapes. But it is entirely unacceptable for busy street views or inside an art gallery.
So Google has come up with a solution: add additional frames between the ones recorded by the Street View cameras. But what should these frames look like?
Today, John Flynn and buddies at Google reveal how they have used the company’s vast machine learning know-how to work out what these missing frames should look like, just be studying the frames on either side. The result is a computational movie machine that can turn more or less any sequence of images into smooth running film by interpolating the missing the frames.
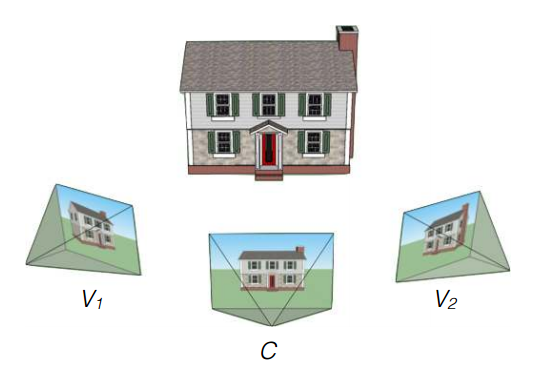
The challenge Flynn and co set themselves is straightforward. Given a set of images of a particular place, the goal is to synthesize a new image of the same area from a different angle of view.
That’s not easy. “An exact solution would require full 3-D knowledge of all visible geometry in the unseen view which is in general not available due to occluders,” say Flynn and co.
Indeed, it’s a problem that computer scientists have been scratching their heads over for decades and one that is closely related to the problem of estimating the 3-D shape of a scene given two or more images of it.
Computer scientists have developed various ways of solving this problem but all suffer from similar problems, particularly where information is lacking due to one object occluding another. This leads to “tearing,” where there is not enough information, and to the disappearance of fine detail. A particular challenge is objects that contain fine detail and are also self-occluding, such as trees.
Flynn and co’s new approach is to train a machine vision algorithm to work out what the new image should look like having been trained on a vast dataset of sequential images.
The task for the computer is to treat each image as a set of pixels and to determine the depth and color of each pixel given the depth and color of the corresponding pixels in the images that will appear before and after it in the movie.
They trained their algorithm, called DeepStereo, using “images of street scenes captured by a moving vehicle.” Indeed, they use 100,000 of these sequences as a training data set.
They then tested it by removing one frame from a sequence of Street View images and asking it to reproduce it by looking only at the other images in the sequence. Finally, they compare the synthesized image with the one that was removed, giving them a kind of gold standard to contrast it with.
The results are impressive. “Overall, our model produces plausible outputs that are difficult to immediately distinguish from the original imagery,” say Flynn and co.
It successfully reproduces difficult subjects such as trees and grass. And when it does fail, such as with specular reflections, it does so gracefully rather than by “tearing.”
In particular, it handles moving objects well. “They appear blurred in a manner that evokes motion blur,” they say.
The method isn’t perfect, however. “Noticeable artifacts in our results include a slight loss of resolution and the disappearance of thin foreground structures,” say the Google team. And partially occluded subjects tend to be overblurred in the output.
It is also computationally intensive. Flynn and co say it takes 12 minutes on a multicore workstation to produce a single newly synthesized image. So these images cannot be produced on the fly. However, the team expects to improve this in future by optimizing the image generation process.
That’s impressive work that once again shows the potential of deep learning techniques. The team show off their results in the video posted here, which shows movies made from Street View data.
But it should also have other applications in generating content for teleconferencing, virtual reality and cinematography. It could even reduce the work load for stop frame animators.
Either way, expect to see Google Street View travel movies flood the Web in the not-too-distant future.
Sources:
- http://www.theregister.co.uk/2015/07/07/google_goes_3d_with_deepstereo/
- http://www.technologyreview.com/view/539051/googles-deep-learning-machine-learns-to-synthesize-real-world-images/
- http://arxiv.org/abs/1506.06825